HA Keycloak Deployment on Kubernetes
Florian Lüscher
Keycloak ist das Open Source Upstream Projekt für Red Hat SSO, welche von vielen Firmen eingesetzt wird. Auch wir haben es bereits in Projekten eingesetzt. In diesem Blogbeitrag zeigen wir, wie wir das Setup für unser High Availabilty Setup auf der Google Kubernetes Engine konfiguriert haben.
Die Applikation hat ca. 3500 Concurrent User, welche sich üblicherweise morgens anmelden und anschliessend den ganzen Tag eingelogged bleiben. Die erwartete Last ist also relativ gering, die Applikation muss jedoch hochverfügbar ausgelegt sein. Dazu betreiben wir in unserem Google Kubernetes Engine Cluster zwei Keycloak Instanzen.
Keycloak Standalone Cluster Mode
Keycloak speichert die Konfiguration, wie beispielsweise die Realms, Benutzer und Gruppenzugehörigkeiten in einer Datenbank. Die eigentlichen Sessions jedoch werden in einem Infinispan Data Grid abgelegt. Das bedeutet, dass wir Keycloak im Cluster Mode betreiben müssen damit wir sicherstellen können, dass die Sessions der Benutzer auf jeder Keycloak Instanz erkannt werden.
Keycloak bietet schon Dockerimages welche wir ebenfalls verwenden.
Der Standalone Cluster Mode im Dockerimage jboss/keycloak kann aktiviert werden,
indem mittels der Umgebungsvariable JGROUPS_DISCOVERY_PROTOCOL ein Discovery Protokoll
konfiguriert wird, über welches sich die Mitglieder eines Keycloak Clusters gegenseitig finden.
Wir verwenden dns.DNS_PING, so dass die Keycloak Instanzen andere Clustermitglieder über einen DNS Lookup ermitteln können. Pod IPs können jedoch nicht über einen
regulären Kubernetes Service ermittelt werden, da für diesen eine neue ClusterIP erzeugt wird. Daher erstellen wir zwei Kubernetes Services. Einen regulären und
einen Headless-Service (clusterIP: None)
kind: Service
apiVersion: v1
metadata:
name: keycloak-service
spec:
selector:
app: keycloak
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: NodePort
---
kind: Service
apiVersion: v1
metadata:
name: keycloak-cluster
spec:
selector:
app: keycloak
clusterIP: None
ports:
- protocol: TCP
port: 80
targetPort: 8080
Die Funktionsweise der beiden Services ist im folgenden Bild zu sehen.
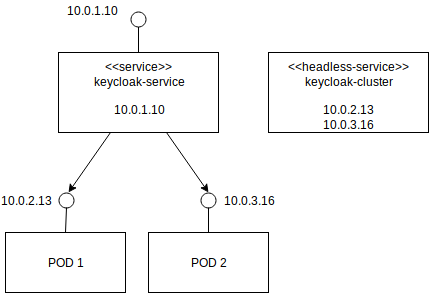
Diese beiden Services erlauben es zum einen den regulären Anwendungen auf die Keycloak Interfaces zuzugreifen, indem sie auf keycloak-service.default.svc.cluster.local verbinden. Dieser DNS Record löst auf eine einzelne Cluster IP auf, welche die Anfragen zwischen den Keycloak Instanzen Load Balanced:
/# dig keycloak-service.default.svc.cluster.local
; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> keycloak-service.default.svc.cluster.local
;; QUESTION SECTION:
;keycloak-service.default.svc.cluster.local. IN A
;; ANSWER SECTION:
keycloak-service.default.svc.cluster.local. 30 IN A 10.43.248.49
Um jedoch alle Clustermitglieder mit den jeweiligen IPs zu erhalten, können wir auf den headless Service zugreifen und erhalten alle IPs der Pods:
/# dig keycloak-cluster.default.svc.cluster.local
; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> keycloak-cluster.default.svc.cluster.local
;; QUESTION SECTION:
;keycloak-cluster.default.svc.cluster.local. IN A
;; ANSWER SECTION:
keycloak-cluster.default.svc.cluster.local. 30 IN A 10.40.2.7
keycloak-cluster.default.svc.cluster.local. 30 IN A 10.40.4.4
Dies erlaubt es Keycloak auf die einzelnen Clustermitglieder zuzugreifen.
JGROUPS_DISCOVERY_PROTOCOL="dns.DNS_PING"
JGROUPS_DISCOVERY_PROPERTIES="dns_query=keycloak-cluster.default.svc.cluster.local"
Deployment bei einem Cloud Provider
Die bisherige Konfiguration kann in einem On-Premise Kubernetes oder OpenShift Cluster funktionieren. Da Keycloak standardmässig jedoch UDP Multicast verwendet,
um innerhalb des Clusters zu kommunizieren funktioniert dieses Setup bei den Cloud Providern nicht, da sie UDP Multicast nicht unterstützen. Keycloak kann aber so
konfiguriert werden, dass TCP verwendet wird. Dazu müssen wir folgende Zeile des Files /opt/jboss/tools/cli/jgroups/discovery/default.cli im Dockerimage hinzufügen.
# GKE does not allow multicast traffic on the network. Use JGroups TCP
/subsystem=jgroups/channel=ee:write-attribute(name="stack", value="tcp")
Wir machen das, indem wir ein eigenes Dockerimage erstellen und das File gleich komplett ersetzen:
FROM jboss/keycloak:4.5.0.Final
COPY ./default.cli /opt/jboss/tools/cli/jgroups/discovery/default.cli
Diese Konfiguration wird erheblich einfacher, sobald unser Pull Request gemerged ist.
Kubernetes Deyployment
Wir betreiben einen Cluster mit Nodes in allen Zonen einer Google Cloud Region. Damit wir den Ausfall von Nodes tolerieren können, stellen wir mit der Pod-Anti-Affinity sicher, dass keine zwei Keycloak Instanzen auf dem gleichen physikalischen Node gescheduled werden.
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- keycloak
topologyKey: "kubernetes.io/hostname"
Falls nun ein Node des Clusters ausfällt, haben wir immer noch eine Instanz auf einem anderen Node. Standardmässig werden die User Sessions gleichmässig auf den Nodes verteilt, eine Replikation
findet jedoch nicht statt. Daher verlieren wir bei einem Ausfall eines Nodes die darauf abgelegten Sessions und die betroffenen Benutzer müssten sich neu anmelden.
Um die Verfügbarkeit wirklich gewährleisten zu können wollen wir die Sessions auf den
Keycloak Instanzen replizieren. Wir erreichen das über eine erneute Erweiterung des Files /opt/jboss/tools/cli/jgroups/discovery/default.cli:
# Make cache items highly available
/subsystem=infinispan/cache-container=keycloak/distributed-cache=sessions:remove()
/subsystem=infinispan/cache-container=keycloak/distributed-cache=authenticationSessions:remove()
/subsystem=infinispan/cache-container=keycloak/distributed-cache=offlineSessions:remove()
/subsystem=infinispan/cache-container=keycloak/distributed-cache=clientSessions:remove()
/subsystem=infinispan/cache-container=keycloak/distributed-cache=offlineClientSessions:remove()
/subsystem=infinispan/cache-container=keycloak/distributed-cache=loginFailures:remove()
/subsystem=infinispan/cache-container=keycloak/replicated-cache=sessions:add()
/subsystem=infinispan/cache-container=keycloak/replicated-cache=authenticationSessions:add()
/subsystem=infinispan/cache-container=keycloak/replicated-cache=offlineSessions:add()
/subsystem=infinispan/cache-container=keycloak/replicated-cache=clientSessions:add()
/subsystem=infinispan/cache-container=keycloak/replicated-cache=offlineClientSessions:add()
/subsystem=infinispan/cache-container=keycloak/replicated-cache=loginFailures:add()
Fazit
Durch unser Setup sind wir in der Lage bei einem Ausfall eines Kubernetes-Nodes erreichbar zu bleiben. So können für die Benutzer einen unterbrechungsfreien Betrieb garantieren.
Möchten Sie eine bestehende oder neue Anwendung auf Kubernetes migriren? Wir beraten Sie gerne.